Prerequisites
Private server with 8 or 12 cores (8 or up to 12 virtual CPU if your server is a virtual machine).
Install Ollama + LLM models
To easily manager LLM model you can install Ollama. It’s easier to manage than llama.cpp but a little less quick (around 20% performance less).
[root@llm ~]# curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
>>> Downloading Linux amd64 bundle
######################################################################## 100,0%
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.If your server doesn’t have GPU, the ollama installer will warn you “Ollama will run in CPU-only mode“.
We can install model codellama tagged 7b (for 7 billion parameters).
[root@llm ~]# ollama run codellama:7b
pulling manifest
pulling 3a43f93b78ec... 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 3.8 GB
pulling 8c17c2ebb0ea... 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 7.0 KB
pulling 590d74a5569b... 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 4.8 KB
pulling 2e0493f67d0c... 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 59 B
pulling 7f6a57943a88... 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 120 B
pulling 316526ac7323... 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 529 B
verifying sha256 digest
writing manifest
success
>>> /bye
[root@llm ~]#We can also install deepseek-coder with 1.3B parameters, because it has less parameters it will be faster but still with quality: ollama run deepseek-coder
Configure the Ollama API
The Ollama API support GET and POST method:
POST /api/generate- GET
/api/tags
You can test the ollama API locally:
[root@llm ~]# curl http://localhost:11434/api/tags
{"models":[{"name":"codellama:7b","model":"codellama:7b","modified_at":"2025-04-17T16:33:25.752300427+02:00","size":3825910662,"digest":"8fdf8f752f6e80de33e82f381aba784c025982752cd1ae9377add66449d2225f","details":{"parent_model":"","format":"gguf","family":"llama","families":null,"parameter_size":"7B","quantization_level":"Q4_0"}}]}Open the ollama listening port to your private network:
[root@llm ~]# firewall-cmd --add-port=11434/tcp --permanent
success
[root@llm ~]# firewall-cmd --reload
successYou can test, but you’ll get an error:
[root@llm ~]# curl http://llm.yourdomain.com:11434/api/tags
curl: (7) Failed to connect to llm.yourdomain.com port 11434: Connexion refusée
[root@llm ~]# systemctl status ollama
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; preset: disabled)
Active: active (running) since Thu 2025-04-17 16:14:02 CEST; 54min ago
Main PID: 34775 (ollama)
Tasks: 17 (limit: 153159)
Memory: 3.6G
CPU: 1min 285ms
CGroup: /system.slice/ollama.service
└─34775 /usr/local/bin/ollama serve
avril 17 16:33:28 llm ollama[34775]: llama_kv_cache_init: kv_size = 8192, offload = 1, type_k = 'f16', type_v = 'f16', n_layer = 32, can_shift = 1
avril 17 16:33:29 llm ollama[34775]: llama_kv_cache_init: CPU KV buffer size = 4096.00 MiB
avril 17 16:33:29 llm ollama[34775]: llama_init_from_model: KV self size = 4096.00 MiB, K (f16): 2048.00 MiB, V (f16): 2048.00 MiB
avril 17 16:33:29 llm ollama[34775]: llama_init_from_model: CPU output buffer size = 0.55 MiB
avril 17 16:33:29 llm ollama[34775]: llama_init_from_model: CPU compute buffer size = 560.01 MiB
avril 17 16:33:29 llm ollama[34775]: llama_init_from_model: graph nodes = 1030
avril 17 16:33:29 llm ollama[34775]: llama_init_from_model: graph splits = 1
avril 17 16:33:30 llm ollama[34775]: time=2025-04-17T16:33:30.039+02:00 level=INFO source=server.go:619 msg="llama runner started in 4.02 seconds"
avril 17 16:33:30 llm ollama[34775]: [GIN] 2025/04/17 - 16:33:30 | 200 | 4.245900053s | 127.0.0.1 | POST "/api/generate"
avril 17 17:01:00 llm ollama[34775]: [GIN] 2025/04/17 - 17:01:00 | 200 | 937.782µs | 127.0.0.1 | GET "/api/tags"You need to allow all IP on your private network, the easier way is to allow all IP (because you are in a private network and your server is protected because it is not public). To do this, just edit the systemd service and add the following environement variable Environment=”OLLAMA_HOST=0.0.0.0″ under the [Service] tag:
[root@llm ~]# systemctl edit --full ollama.serviceYou’ll save the following file:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin"
[Install]
WantedBy=default.targetReload systemd configuration and restart ollama:
[root@llm ~]# systemctl daemon-reload
[root@llm ~]# systemctl restart ollama
[root@llm ~]# curl http://llm.yourdomain.com:11434/api/tags
{"models":[{"name":"codellama:7b","model":"codellama:7b","modified_at":"2025-04-17T16:33:25.752300427+02:00","size":3825910662,"digest":"8fdf8f752f6e80de33e82f381aba784c025982752cd1ae9377add66449d2225f","details":{"parent_model":"","format":"gguf","family":"llama","families":null,"parameter_size":"7B","quantization_level":"Q4_0"}}]}You can curl the api from your laptop, or access it via a web browser: http://llm.yourdomain.com:11434/api/tags
Access your LLM in your VSCode
Install the “Continue” extension.
Edit the settings file config.yaml. If you don’t see it in VSCode you can also directly access it (on windows it is here: C:\Users\<your_user>\.continue\config.yaml).
name: Local Assistant
version: 1.0.0
schema: v1
models:
# Auto detect your local models if you have some
- name: Autodetect
provider: ollama
model: AUTODETECT
# Add you remote codellama model
- name: Test remote ollama
provider: ollama
apiBase: http://llm.yourdomain.com:11434
model: codellama:7b
capabilities:
- tool_use
- image_input
roles:
- chat
- edit
- apply
- summarize
# Add your remode Deepseek-coder:
- name: Remote Deepseek-coder
provider: ollama
apiBase: http://llm.yourdomain.com:11434
model: deepseek-coder:latest
context:
- provider: code
- provider: docs
- provider: diff
- provider: terminal
- provider: problems
- provider: folder
- provider: codebase
Now you can select your remode model:
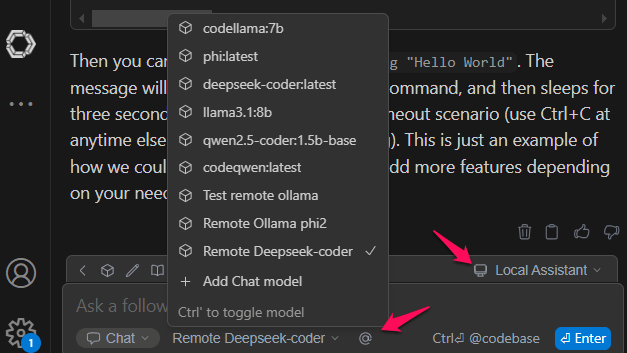
You’ll see that you need a lot of CPU cores to have answers in less than 1 minute… but if you have a powerful server with GPU I imagine it can be very good.
1 Pingback