
This post follow the previous one you should read it in order to configure a LLM on your private server.
First we create a userdev in which we will create our API for RAG. We create virtual python environment to ensure no conflict with the python system of your server (you can install python libraries without risk) and also to ensure separation between this project and potential future projects.
useradd userdev su - userdev mkdir rag_api cd rag_api python3 -m venv .venv source .venv/bin/activate
Now we can install depencies and generate a requirements.txt file:
pip install fastapi gunicorn uvicorn langchain langchain-community chromadb requests pip freeze > requirements.txt
Then you’ll be able to restore these requirements later with the following command:
pip install -r requirements.txt
explanation about the dependencies:
- chromadb: the vectorial database, the python library chromadb includes a database engine. No need to install a ‘chroma’ database on your server, it is all managed by this python library.
- langchain: it is used for text splitting
- fastapi: library to develop a python api
- uvicorn is an ASGI web server for local test
- gunicorn is an ASGI web server for production
We create a directory in which vertor database will store its data: /home/userdev/rag_api/vectordb
Also we put data in a directory for our RAG: /home/userdev/rag_api/my_repo
Data can be for instance source code from a git repository.
Now we need to create an API to manage RAG:
from fastapi import FastAPI, Request
from pydantic import BaseModel
from fastapi.middleware.cors import CORSMiddleware
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OllamaEmbeddings
from langchain.vectorstores import Chroma
from pathlib import Path
import requests
import os
# === CONFIGURATION ===
OLLAMA_API_URL = "http://localhost:11434/api/generate"
EMBED_MODEL = "deepseek-coder:1.3b"
LLM_MODEL = "deepseek-coder"
VECTOR_DB_DIR = "/home/userdev/rag_api/vectordb" # directory in which the vectordb is stored
SOURCE_CODE_DIR = "/home/userdev/rag_api/my_repo" # your source code repository for RAG
CHUNK_SIZE = 512
CHUNK_OVERLAP = 50
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
class PromptRequest(BaseModel):
prompt: str
# === UTILS RAG ===
def load_code_files(source_dir):
code = []
extensions = {".py", ".js", ".ts", ".java", ".xml", ".cpp", ".c", ".go", ".rs"}
for path in Path(source_dir).rglob("*"):
if path.suffix in extensions:
try:
with open(path, "r", encoding="utf-8") as f:
content = f.read()
code.append(content)
except Exception as e:
print(f"Erreur avec {path}: {e}")
return "\n\n".join(code)
def split_code(text):
splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
return splitter.split_text(text)
def create_vectorstore(chunks):
embedding = OllamaEmbeddings(model=EMBED_MODEL)
vectordb = Chroma.from_texts(chunks, embedding=embedding, persist_directory=VECTOR_DB_DIR)
vectordb.persist()
return vectordb
def retrieve_context(query, k=3):
embedding = OllamaEmbeddings(model=EMBED_MODEL)
vectordb = Chroma(persist_directory=VECTOR_DB_DIR, embedding_function=embedding)
docs = vectordb.similarity_search(query, k=k)
return "\n\n".join([doc.page_content for doc in docs])
def ask_ollama(prompt):
payload = {
"model": LLM_MODEL,
"prompt": prompt,
"stream": False
}
response = requests.post(OLLAMA_API_URL, json=payload)
return response.json().get("response", "Erreur ou réponse vide.")
# === ENDPOINT POUR POSER UNE QUESTION ===
@app.post("/rag")
def rag_endpoint(req: PromptRequest):
context = retrieve_context(req.prompt)
final_prompt = f"""Voici du code extrait de ton repository :
{context}
Question :
{req.prompt}
Réponds de manière claire et précise."""
answer = ask_ollama(final_prompt)
return {"response": answer}
# === ENDPOINT POUR RÉINDEXER LE CODE ===
@app.post("/index")
def index_repo():
print("📁 Indexation du repo...")
code = load_code_files(SOURCE_CODE_DIR)
chunks = split_code(code)
create_vectorstore(chunks)
return {"status": "✅ Indexation terminée"}
Start the gunicorn server from within your activated python virtual environment:
gunicorn rag_api:app --workers 1 --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0:8000 --daemon
explanation on the gunicorn parameters:
- rag_api:app is the app we load in the gunicorn server
- –bind 0.0.0.0:8000 means the webserver will listen from every source on port 8000
- –daemon is used to launch the webserver as a daemon (a background process that will not be quitted when you exit your terminal session)
Now to expose this API to outside requests, we use apache httpd as a frontal webserver. We define the following virtual host:
<VirtualHost *:80>
ServerName ragllm.codetodevops.com
ProxyPreserveHost On
ProxyPass / http://127.0.0.1:8000/
ProxyPassReverse / http://127.0.0.1:8000/
ErrorLog /var/log/httpd/rag_error.log
CustomLog /var/log/httpd/rag_access.log combined
</VirtualHost>
Now you can use postman to make a call to POST /index route in order to index your data:
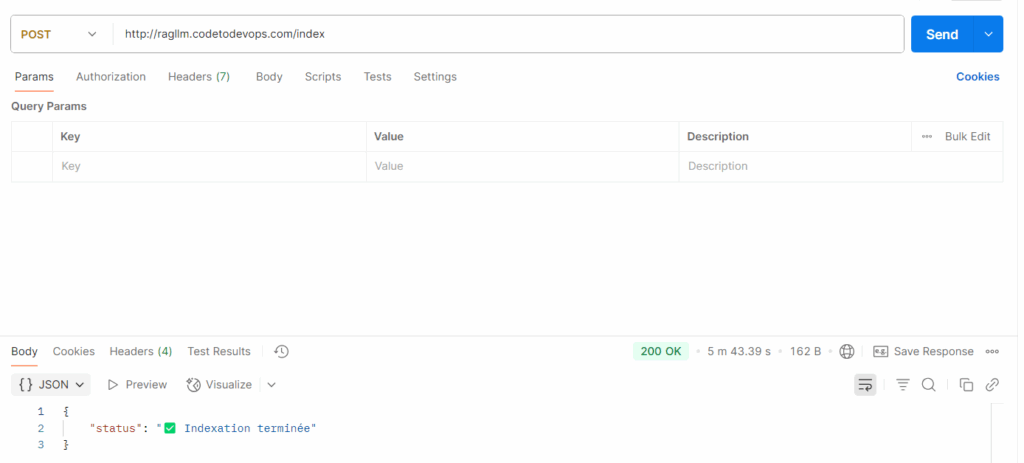
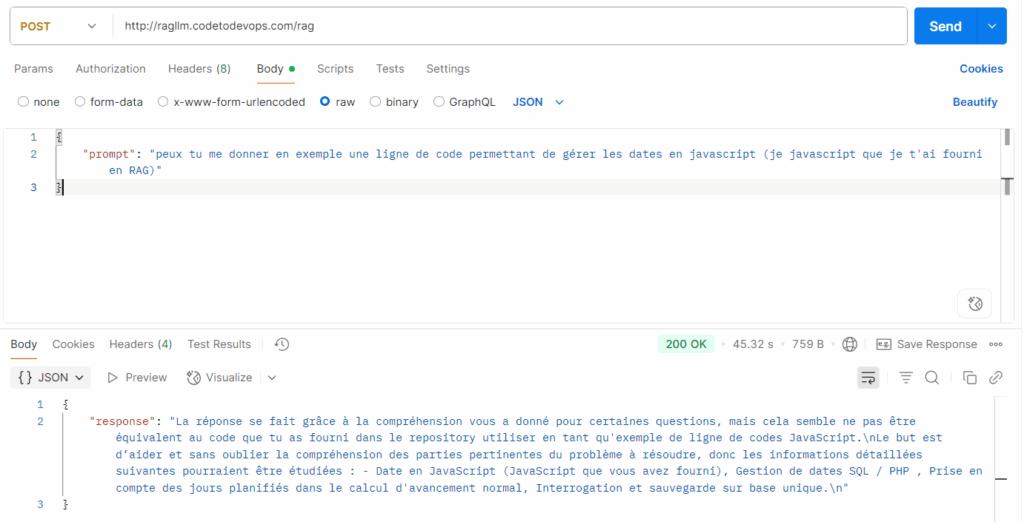
Once your data has been indexed, you can query as much as you want your RAG system:
Leave a Reply